I thought I was building a router.
What I was building was a way to explain model decisions.
I've been running multi-agent systems at home for a while. Nix on the NAS, Max on the Mac Mini. Both hit Claude, OpenAI, and MiniMax as some of my LLM providers, with Ollama serving Qwen and Gemma locally at other points. At some point I noticed that every request was landing on the same model. Same cost. Same latency. No visibility into why.
The obvious answer was routing. The harder part started one layer later.
#The problem with default-model agents
Most agent runtimes start with a reasonable shortcut: pick a strong default model and move on.
That works for a while. It's simple, predictable, and easy to wire into the runtime. But as soon as the agent starts doing a mix of chat, planning, tool-heavy execution, debugging, and longer task workflows, that simplicity starts hiding real tradeoffs.
Three problems at once:
- cheap requests ride an expensive path
- stronger models get used when they're not actually needed
- when behavior changes, it's hard to tell whether the cause was the prompt, the runtime, the tools, or the model choice
The third one is the trap.
If latency goes up, or answers get shallower, or cost drifts over time, you need more than a billing export and a vague memory of what changed. You need to know which model the runtime asked for, which model actually ran, and what routing rule fired.
Without that, routing is just another hidden subsystem.
#Mux: the policy layer
I wanted runtimes to keep a stable calling interface while model choice moved into a separate policy layer.
agent runtime (Max, Nix)
→ Mux (OpenAI-compatible endpoint)
→ policy decision (heuristic match)
→ provider dispatch (Anthropic SDK / LiteLLM)
→ AgentWeave trace (routing metadata + latency + tokens)
Mux sits between agent runtimes and model backends. It exposes an OpenAI-compatible endpoint to the client, then resolves and dispatches downstream according to policy. Provider auth - including Anthropic OAuth - is handled centrally instead of every runtime needing its own integration. That centralization turned out to be more important than the routing itself. If you have multiple runtimes, provider auth and transport logic become duplication very quickly. One control point eliminates that.
The runtime doesn't know or care which model runs. It sends a request. Mux decides.
#The policy: Haiku, Sonnet, Opus
The routing logic is intentionally simple right now. For Anthropic-family requests coming from Max:
- simple lightweight prompt → Haiku
- coding or execution-oriented prompt → Sonnet
- deep reasoning / planning / architecture prompt → Opus
The Max routing heuristic looks like this:
// Only check the LAST user message - system prompts and conversation
// history contain keywords that falsely escalate.
const lastUserMsg = [...req.messages].reverse().find(m => m.role === "user");
const transcript = typeof lastUserMsg?.content === "string"
? lastUserMsg.content : JSON.stringify(lastUserMsg?.content);
if (containsMaxDeepReasoningCue(transcript)) {
// "architecture", "tradeoff", "strategy", "roadmap", "plan"...
return { resolvedModel: "claude-opus-4-6",
routeReason: "heuristic:max_anthropic_deep_reasoning" };
}
if (containsMaxCodingCue(transcript)) {
// "debug", "implement", "deploy", "fix this", "refactor"...
return { resolvedModel: "claude-sonnet-4-6",
routeReason: "heuristic:max_anthropic_coding" };
}
if (isSimplePrompt(req)) { // last user message < 80 chars
return { resolvedModel: "claude-haiku-4-5-20251001",
routeReason: "heuristic:max_anthropic_haiku_simple" };
}
Simple on paper. Not simple to get right.
The first version had predictable problems. System prompts polluted the signal. Conversation history carried old keywords forward and triggered false escalation. Some task-oriented prompts were short enough to look lightweight even when they were clearly real work. Tool presence was noisy because Max always sends its full toolset, even for trivial turns.
So the policy had to get more disciplined.
The current version leans much more heavily on the last user message instead of the whole transcript. That sounds like a tiny implementation detail. It's the difference between a demo heuristic and a router you can trust.
The lesson: routing quality isn't mostly about having clever buckets. It's about reducing the amount of misleading context that the policy sees.
#Max as the proving ground
We've posted about Max before. Desktop-side agent on the Mac Mini. Browser work, local tooling, desktop automation, longer-running tasks. That makes Max a good proving ground for routing because it produces a genuine mix of simple chat, coding tasks, and planning prompts throughout the day.
With Mux enabled, Max keeps one simple client behavior while Mux decides what runs underneath. A clean boundary:
- Max owns agent behavior, tools, and task execution
- Mux owns model policy
- AgentWeave owns the trace of what happened
Without that boundary, the temptation is to sprinkle model-selection logic directly into the runtime. That works briefly, then becomes a mess. The runtime starts knowing too much about provider quirks, routing heuristics, fallback behavior, and cost tradeoffs.
Max is just the current example. The pattern is the point: any runtime should be able to keep a stable interface while delegating model choice to a shared policy layer.
#The moment it clicked
I'd been running Mux for about a week before I opened the AgentWeave routing view for the first time.
The numbers surprised me.
Out of 50 requests routed in one hour: 36 were redirected. Only 14 kept the originally requested model. Two routing reasons accounted for nearly everything: max_anthropic_coding and max_anthropic_haiku_simple.
Short, simple prompts correctly routed to Haiku. Coding-related prompts stayed on Sonnet. Deeper reasoning tasks escalated to Opus. The heuristic was holding up in practice, not just in theory.
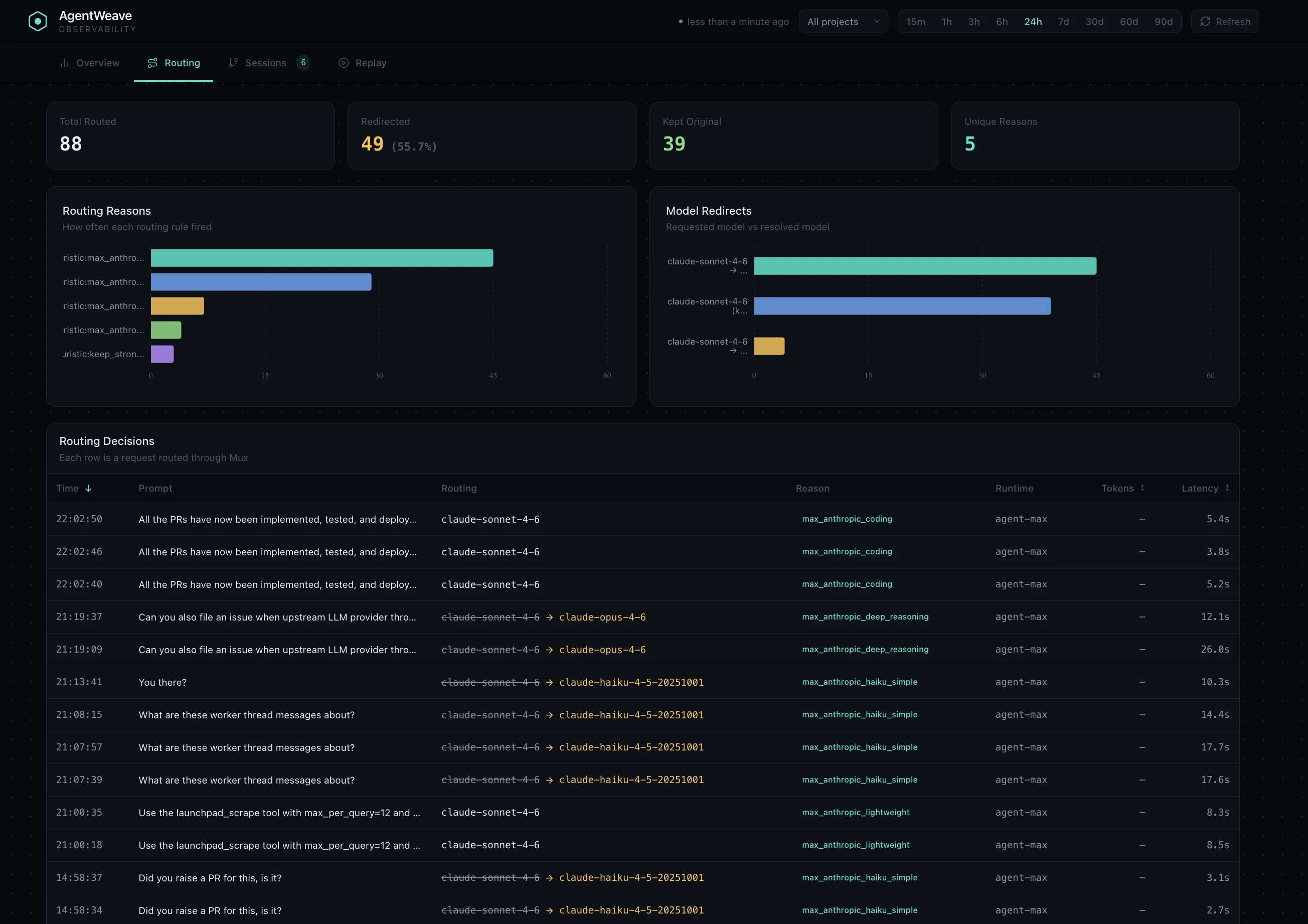
What surprised me was how much Haiku was handling. Nearly half the redirected traffic was going to Haiku - prompts I'd been sending to Sonnet by default for months. Not because Sonnet was needed, but because I'd never had a way to see which prompts were actually lightweight.
That's when I realized routing wasn't the core problem. The explanation was.
#The explanation layer
This is the part I underestimated.
The hard part isn't choosing between three models. The hard part is making that choice legible later.
If you notice higher latency, worse answers, increased cost, or different behavior between runtimes, the debugging path can't stop at "routing happened." You need to know what the runtime asked for, what Mux resolved it to, why it made that decision, and whether this was an isolated case or a repeated pattern.
That's what AgentWeave gives you. For each request routed through Mux, the trace captures:
setSpanAttrs({
"prov.route.requested_model": route.requestedModel,
"prov.route.resolved_model": route.resolvedModel,
"prov.route.reason": route.routeReason,
"prov.route.runtime": runtime,
"prov.llm.prompt_preview": promptPreview, // first 200 chars
"prov.route.message_count": body.messages.length,
});
That changes the nature of routing. Now I can look at routing decisions and ask real questions:
- How often are simple prompts getting downgraded to Haiku?
- Are coding prompts being misrouted when they shouldn't be?
- Is one runtime producing prompts that bias the policy the wrong way?
- What's the actual cost distribution across models?
That's a completely different feedback loop from "cost felt high this week."
That last part is the difference between a clever gateway and a system you can trust.
#The architecture that emerged
After building this, the cleanest split looks like this:
Mux - the policy/control layer. Accepts a stable runtime-facing request shape. Centralizes provider auth and downstream dispatch. Applies routing policy. Emits routing metadata.
AgentWeave - the observability/provenance layer. Traces the request path. Records routing attributes. Visualizes redirects and reasons. Makes policy behavior debuggable.
Mux should not become a dashboard. AgentWeave should not become a policy engine.
One decides. The other explains.
#What's next
The Max + Anthropic setup is the first working slice, not the final shape.
- Multi-provider routing - Anthropic OAuth as one downstream path, LiteLLM-backed OpenAI and Gemini as others. Runtimes like Max and Nix hit one shared endpoint regardless of provider.
- Delegated session routing - recognizing child-session requests so sub-agent traffic gets its own policy treatment.
- OpenClaw integration - bringing Nix through the same routing path so both agents share a single policy layer.
- Richer instrumentation - continuing to deepen telemetry across the OpenAI-compatible path as it matures.
The architecture already points there. Adding more provider paths is an extension of the design, not a reinvention of it.
#The takeaway
I thought I was building a router.
What I was building was a way to make model choice understandable.
Routing between Haiku, Sonnet, and Opus is useful. Anthropic OAuth through a shared control point is useful. Max is a good real-world proof point for both.
But the part that feels durable is the split:
- a policy layer that runtimes can delegate model choice to
- a clean provider integration path behind that layer
- and an observability layer that shows not just what happened, but why
Not just model routing.
An explanation layer for model routing.
Repo: github.com/arniesaha/mux