Managing Kubernetes clusters can be complex, especially when dealing with performance issues, scalability and system bottlenecks. In couple of instances in the recent past, I've encountered significant challenges with EBS CSI (Elastic Block Store Container Storage Interface) controller on Amazon EKS (Elastic Kubernetes Service), primarily related to volume creation slowness and intermittent unresponsiveness of CoreDNS. This article highlights these challenges and the effective management practices that can be adopted to handle such scenarios.
A Kubernetes pod will have to resolve the domain names of both internal and external services for successful communication, and it utilizes the CoreDNS pod for this purpose. The CoreDNS pod then routes the DNS queries through the worker node's (on which the CoreDNS pod is running) ENI for external endpoint resolution. In the case of internal endpoints, the packets will still have to use the worker node's ENI, if the CoreDNS pod is not present in the same worker node as the pod making the DNS query.
#Volume creation on EKS with CoreDNS and EBS CSI Controller
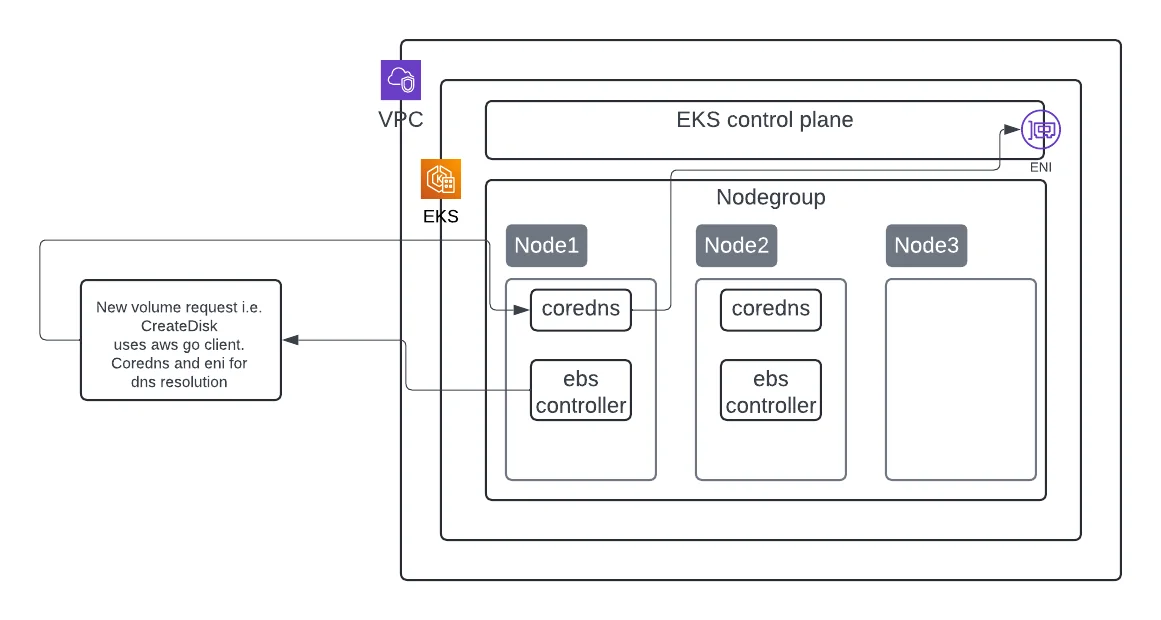
Below links explain queries processing in CoreDNS & EBS CSI controller architecture and VPC CNI (ENI implementation) best practices.
#Symptoms in Production
Primary indicators where several volume requests in pending state, specifically at high load / requests scenarios. Overall erratic in nature and not consistently reproducible.
- Volume Pending
- Timeout - Deadline exceeded
##1. CoreDNS Unresponsiveness
CoreDNS is a critical component in a Kubernetes cluster, responsible for DNS resolution. During an incident, observed intermittent unresponsiveness of CoreDNS, which led to the EBS controller being unable to provision and attach volumes. This issue caused pods to remain in a pending state, disrupting application availability.
##2. Monitoring Gaps
Monitoring DNS throttling and packet drops proved challenging. Metrics for linklocal_allowance_exceeded was not observed and flow logs did not capture all IP traffic, especially traffic generated by instances contacting the Amazon DNS server. This absence of comprehensive logs made it difficult to diagnose the problem accurately.
##3. Microbursts and Network Throttling
Microbursts, characterized by short spikes in network demand, were identified as a common cause of these issues. These bursts often lead to packet drops, which are difficult to monitor due to their transient nature. Network throttling at the elastic network interface level further complicated the situation.
##4. AMI and Kernel Discrepancies
We observed discrepancies between the AMI (Amazon Machine Image) versions and kernel versions used across different clusters. Keeping same versions across different clusters & nodes help in ruling out version related issues easily. In this case, it adds another variable to reduce in the chase for understanding the root-cause of the erratic behavior discussed above.
#Recommendations
##1. CoreDNS Addon and Autoscaling
It's best to manage CoreDNS on EKS via addons. To mitigate CoreDNS unresponsiveness, version compatibility & autoscaling, increase the replica count to an appropriate number suitable for your workload (Default is 2). Managing via add-on improved DNS resolution reliability and availability.
##2. Implementing Comprehensive Monitoring
Collaborating with AWS, we used internal tools to monitor network usage and packet loss. In addition to adding the increased CoreDNS replicas, it is also essential to understand network performance and throttling (if any) by leveraging ENI metrics as part of your monitoring strategy.
While most of us check the CoreDNS logs and metrics in the name of monitoring, customers often forget the hard limit of 1024 packets per second (PPS) set at the ENI level.
##3. Enhancing Logging Capabilities
Leverage centralised logging and observability and enable appropriate log level (i.e. debug) for CoreDNS, EBS CSI controller and your application workload to identify symptoms more proactively.
##4. Implementing NodeLocalDNS
To further enhance DNS performance, we plan to implement NodeLocalDNS, which caches DNS queries locally on each node, reducing latency and improving reliability.
##5. Targeted Tests / QA
We conducted tests to reproduce the issues, including throttling EBS creation and simulating CoreDNS downtime. These tests confirmed that our volume creation processes were functioning correctly even during disruptions, providing valuable insights for future troubleshooting.
##6. Updating and Standardizing AMIs
Standardizing AMI versions and updating to the latest versions with hardened security and performance patches helped mitigate discrepancies. We moved the CSI controller to a dedicated node group running the latest AMI to prevent similar issues.
#Conclusion
Effective management of CoreDNS and EBS controllers on EKS requires a proactive approach to monitoring, logging, and updating infrastructure components. By addressing the challenges we faced and implementing the solutions outlined above, we have significantly improved the performance and reliability of our Kubernetes clusters. These practices ensure that our applications run smoothly, minimizing downtime and enhancing overall user experience.