If you've been following along, you may already know about Nix, my always-on AI assistant running on a NAS. Scheduling, messaging, research digests, cron jobs. It's always on, and for a while, one agent was enough.
Then I set up a second machine: a Mac Mini. Some things just need a desktop. Persistent browser sessions, Chrome automation, a proper GPU pipeline, the ability to actually click things. A NAS couldn't do it reliably.
So I spun up a second agent, Max, on the Mac Mini. Both were running the same framework. They were supposed to talk to each other. They sort of did. And then everything started breaking.
This is what I learned rebuilding it properly.
#Why the First Version Broke
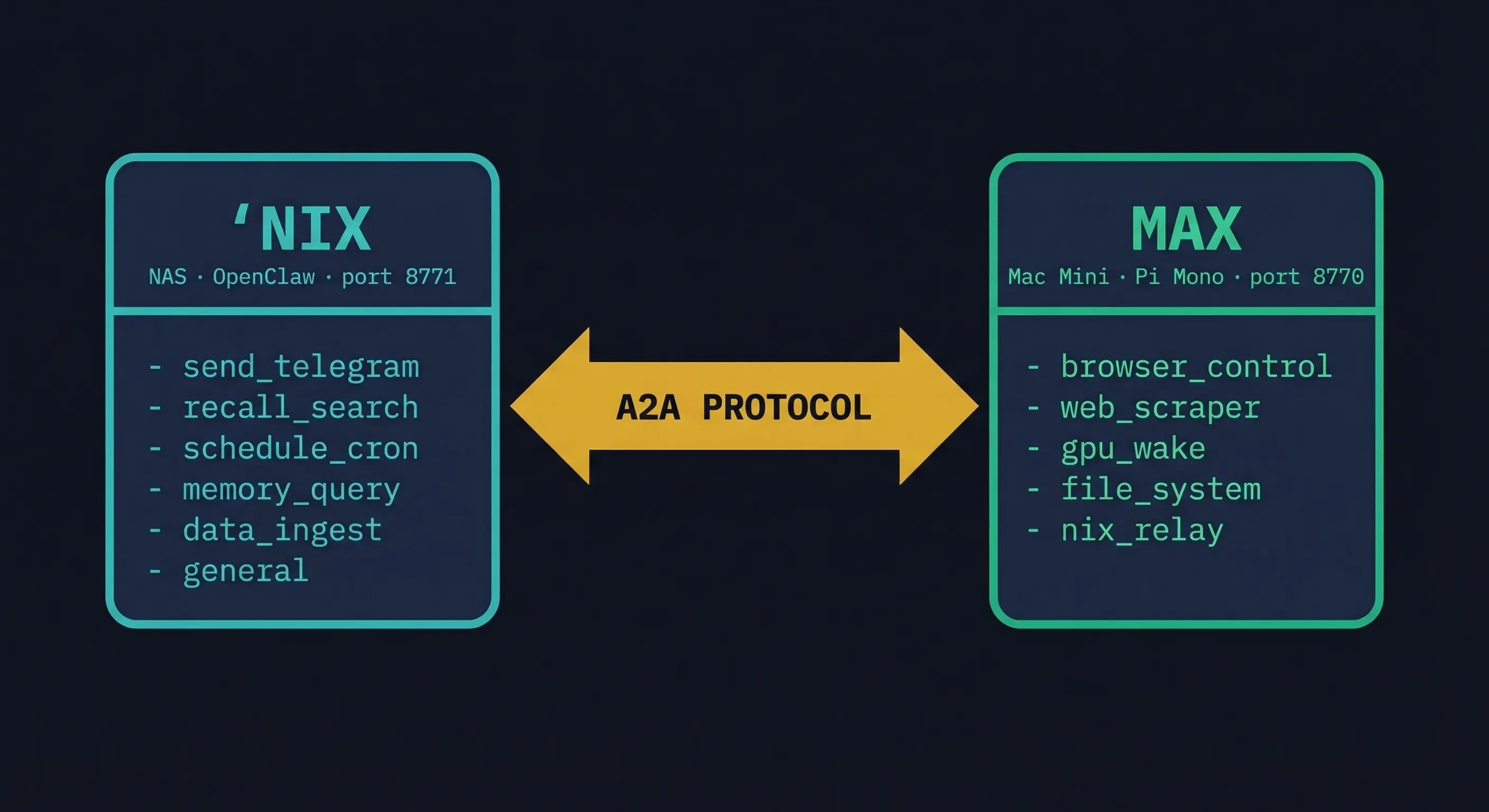
The original setup: two agents, same framework (OpenClaw), communicating via sessions_send. One gateway on the NAS, one on the Mac Mini.
In practice, three things went wrong.
The Mac Mini agent kept crashing. OpenClaw is a full daemon: gateway server, channel plugins, session management, cron, WhatsApp/Telegram connectors. Running two full instances meant competing for memory and doubling the failure surface. Every time I closed a terminal on the Mac Mini, something died.
Communication was unstructured. Agent-to-agent calls were just text messages relayed between sessions. No task IDs, no retry logic, no acknowledgement. A message could fail silently and I would never know.
The frameworks were identical when they shouldn't be. Nix and Max have completely different jobs. Nix is an orchestrator: scheduling, routing, memory, notifications. Max is a specialist: browser automation, local Mac operations. Running the same bloated framework on both ignored that distinction entirely.
The fix was less obvious than I expected: give each agent the framework that matches its job description, then connect them with a real protocol.
#The Rebuild: Right Framework for Each Agent
Nix stays on OpenClaw. It's the orchestrator. OpenClaw handles scheduling, cron, Telegram routing, memory, and Recall search well. The framework's strengths line up with Nix's job.
Max moves to Pi Mono. Mario Zechner's Pi Mono is the opposite of a framework. (Max's full source is on GitHub.) It's a toolkit: an agent loop, a tool registry, and a Telegram bot via Grammy. No daemon, no plugins, no gateway. The whole thing starts in under a second and runs stable as a macOS LaunchAgent.
They communicate via A2A. Google's Agent-to-Agent protocol, now under the Linux Foundation. Not text messages. Not SSH tunnels. A real protocol with task lifecycle, error handling, and agent discovery.
#Pi Mono: What Lightweight Actually Means
Pi Mono's core is almost nothing. That's the point.
import { Agent } from "@mariozechner/pi-agent-core";
import { createLLM } from "@mariozechner/pi-ai";
const llm = createLLM({
provider: "google",
model: "gemini-2.5-pro",
apiKey: process.env.GOOGLE_API_KEY,
});
const agent = new Agent({
name: "Max",
llm,
tools: [browserControl, webScraper, gpuWake, fileSystem, nixRelay],
systemPrompt: await loadMemory(),
});
That's the agent. A loop that calls an LLM, executes tool calls, manages context, repeats. No config files, no plugin lifecycle, no middleware between your code and the model.
A tool is just a TypeScript function with a schema:
const nixRelay: Tool = {
name: "nix_relay",
description: "Delegate a task to Nix's A2A server",
schema: z.object({
skill_id: z.enum(["send_telegram", "recall_search", "data_ingest", "memory_query"]),
message: z.string(),
}),
execute: async ({ skill_id, message }) => {
const resp = await fetch(`${NIX_A2A_URL}/tasks?sync=true`, {
method: "POST",
headers: { Authorization: `Bearer ${A2A_TOKEN}` },
body: JSON.stringify({
id: crypto.randomUUID(),
skill_id,
message: { parts: [{ type: "text", text: message }] },
}),
});
const data = await resp.json();
return data.result?.reply ?? data;
}
};
What I kept from OpenClaw's design patterns: memory as flat markdown files, session continuity via startup reads, scoped workspace operations.
What I dropped: the channel plugin system, cron (Nix handles scheduling for both agents), and the gateway daemon entirely.
The difference in practice: Max's response time dropped noticeably. Not because the hardware changed, because there's no framework overhead between the tool call and execution. The call stack is shallow and readable. When something breaks, there's no black box to debug.
#Building Purpose-Built Skills
The clearest sign the architecture is right: both agents' skill sets are completely non-overlapping.
Max's skills require physical access to the Mac. Real browser sessions with persistent cookies, local file operations, Xcode for iOS builds, Chrome DevTools Protocol. None of this can run on the NAS.
Nix's skills are orchestration. Data storage, scheduling, notifications, memory, knowledge base search. None of this requires a desktop.
This separation made one design decision obvious: when Max produces output that Nix needs to store, it should travel via A2A, not file transfer.
##The Event-Driven Push Pattern
The naive approach to passing data between agents: Agent A scrapes data, saves a file, transfers it to Agent B, Agent B reads the file. Three failure points, a file system dependency, and a polling loop.
The A2A approach: Agent A scrapes, then calls Agent B's ingest skill with the JSON payload directly.
// Max, after scraping completes:
await nixRelay.execute({
skill_id: "data_ingest",
message: JSON.stringify(scrapedResults),
});
// Nix's data_ingest handler:
export async function handleDataIngest(taskId: string, text: string) {
const items = JSON.parse(text);
const db = new Database(DB_PATH);
let ingested = 0;
for (const item of items) {
const exists = db.prepare("SELECT id FROM items WHERE url = ?").get(item.url);
if (!exists) {
db.prepare("INSERT INTO items ...").run(...);
ingested++;
}
}
updateTaskStatus(taskId, "completed", { ingested, total: items.length });
}
Zero file I/O. Zero SSH. Max pushes the event; Nix's A2A server handles it like any other task. The orchestrator detects new rows in the database and continues the pipeline.
This is what event-driven means in a multi-agent context: agents communicate state changes, not files.
#The A2A Protocol: Why Not Just REST?
I could have built a simple REST API on each side. But A2A gives you things a bespoke API does not.
Structured task lifecycle. Every task goes through defined states: submitted, working, completed, or failed. Both agents agree on what a task means.
Agent Cards. Each agent publishes a discovery document at /.well-known/agent.json describing its capabilities. Any agent can find out what another can do without hardcoded knowledge.
{
"name": "Nix",
"url": "http://10.0.0.10:8771",
"skills": [
{ "id": "send_telegram", "description": "Send message to user" },
{ "id": "recall_search", "description": "Search personal knowledge base" },
{ "id": "data_ingest", "description": "Receive and store scraped data" },
{ "id": "schedule_cron", "description": "Create scheduled jobs" },
{ "id": "memory_query", "description": "Search memory files" },
{ "id": "general", "description": "Inject task into main session" }
]
}
SSE streaming. Long-running tasks stream progress events. The caller can watch in real-time or poll.
Sync mode for fast operations. Async by default (submit, get a task ID, poll later) adds unnecessary latency for quick queries. I added ?sync=true to the endpoint: the handler runs inline and returns the result immediately.
# Async (default)
POST /tasks
→ { "id": "task-123", "status": "submitted" }
# Sync
POST /tasks?sync=true
→ { "id": "task-123", "status": "completed", "result": {...} }
Memory lookups, Telegram sends, recall searches: sync. Scraping pipelines, deployments: async with SSE.
#Disaster Recovery Without a Queue
For task durability, the obvious choice is a proper queue: Kafka, RabbitMQ, or any async event system. Ordered delivery, consumer groups, replay on failure. You can build exactly that on top of A2A.
For two agents processing maybe 50 tasks a day, it's also significant operational overhead. I wanted durability without running another service.
SQLite task journal on each side:
CREATE TABLE tasks (
id TEXT PRIMARY KEY,
skill_id TEXT NOT NULL,
status TEXT DEFAULT 'submitted',
message TEXT NOT NULL,
result TEXT,
error TEXT,
created_at INTEGER DEFAULT (unixepoch()),
retry_count INTEGER DEFAULT 0
);
On startup, both agents scan for tasks stuck in working (interrupted mid-execution) and reset them to failed. Retry logic with backoff handles transient failures. Every task is auditable by querying the file directly.
A proper queue is a better choice at scale. At this scale, SQLite is the better choice.
#The Distributed Pipeline
The system running today coordinates both agents in a single pipeline run:
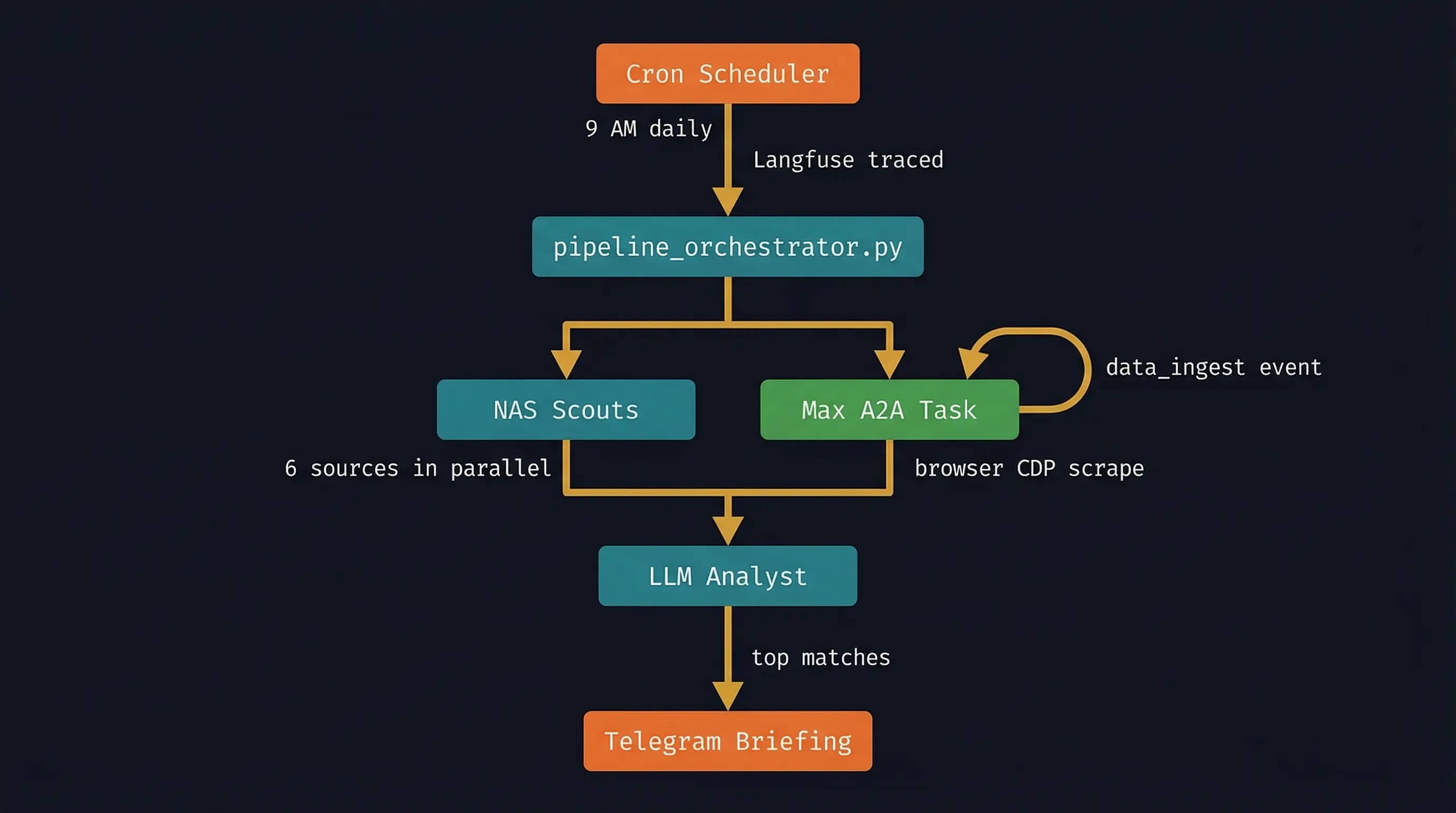
Max and Nix run concurrently. While Max handles the browser-dependent work, Nix runs all the sources it can handle natively. They join at the database. If Max's A2A event doesn't arrive within the timeout window, the pipeline continues with what it has.
Langfuse (self-hosted) traces every run with spans per stage. When something slows down, I can see exactly where.
#What Actually Broke During Build Day
App Nap throttling Max's process. When I closed the terminal, response times jumped. Max was still alive (LaunchAgent kept it running) but macOS was treating the background Node process as low priority. Fix: wrap the launch in caffeinate and declare the process type as Interactive.
<key>ProgramArguments</key>
<array>
<string>/usr/bin/caffeinate</string>
<string>-i</string><string>-s</string>
<string>/opt/homebrew/bin/node</string>
<string>/path/to/agent/dist/index.js</string>
</array>
<key>ProcessType</key>
<string>Interactive</string>
<key>Nice</key>
<integer>-5</integer>
A2A request schema mismatch. Max's server was built independently. His request format used a params wrapper I wasn't expecting:
{
"id": "task-uuid",
"params": {
"message": { "role": "user", "parts": [{ "type": "text", "text": "..." }] },
"metadata": {}
}
}
That's JSON-RPC 2.0 convention. I spent 20 minutes trying field name combinations before realising Max had already told me the format by example, in his own requests to Nix.
#Proof It Works
By the time the Nix A2A server came up, Max had already sent four tasks to it unprompted. Connectivity test, memory queries, status checks. He'd been poking at the endpoint since it appeared on the network.
I asked Max for his week summary via Nix's outbound A2A call:
"The biggest thing this week was moving from OpenClaw to Pi-mono. Model upgraded to Gemini 2.5 Pro. I ran the scraper successfully but couldn't push the results because my SSH to the NAS is broken since the migration. We debugged the A2A setup today and it's working."
An agent on a Mac Mini, queried by an agent on a NAS, over a structured protocol, returning a coherent summary of its own week. Neither in the loop.
The end-to-end test was cleaner: a task submitted to Max triggered a real web scrape, the results came back via nix_relay to data_ingest, and the database reflected the new rows within 30 seconds. No file transfers. No SSH calls.
#What I Would Do Differently
Start with the skill taxonomy. Before writing any code, list every operation each agent needs to perform. If the same operation appears on both lists, something is wrong: it belongs on one side, or it needs its own agent.
Write the Agent Card before the implementation. It's the API contract. Max knowing Nix has data_ingest changed how Max was built.
Don't fight the framework boundary. The temptation is to give every agent every capability just in case. Resist it. Each agent having a clearly defined communication role — Max for direct interaction, Nix for orchestrated notifications and cron alerts — means there's no ambiguity about who sends what. That's a feature.
#What's Next
More agents, same pattern. The A2A server is reusable. A research agent for deep paper analysis, a code review agent for automated PR triage. Each runs lightweight on the right hardware, publishes a card, speaks A2A.
Nix delegating deployments to Max. Docker builds are CPU-bound. Max's M4 is faster than the NAS at compilation. Nix should hand off k8s deploys via A2A rather than doing them locally.
At some point the agent coordination itself becomes complex enough that it needs an agent managing it. We're not there yet. But the infrastructure is ready for it.
#The Lesson
Single-agent systems are simpler. If you can get away with one agent doing everything, do that.
When you need two machines with fundamentally different capabilities, you need two agents. And when you have two agents, the framework and protocol choices matter more than you expect.
Pi Mono showed me that a smaller framework is a design decision, not a compromise. You trade convenience features for legibility, control, and speed. For a specialist agent with a fixed skill set, that's the right trade.
A2A showed me that agent communication should be first-class from the start. Task lifecycle, error handling, and agent discovery belong in the protocol, not bolted on top of the application code.
Two agents. Two frameworks. One protocol.
Nix runs on a NAS. Max runs on a Mac Mini M4. OpenClaw powers Nix. Pi Mono powers Max. agent-max source on GitHub.